LLM Cache: The Secret Weapon You’re Overlooking
Discover how LLM Caching can supercharge your AI performance and slash response times by up to 80%!
In this comprehensive guide, we’ll dive deep into the world of LLM (Large Language Model) Caching, a game-changing technique that’s revolutionizing AI performance.
You’ll learn what LLM Caching is, why it’s crucial for modern AI systems, and how to implement it effectively. We’ll explore different caching strategies, compare caching in AI Agents vs. RAG Architectures, and provide hands-on examples using popular libraries like LangChain and GPTCache. By the end of this article, you’ll have the knowledge to significantly boost your AI system’s speed, reduce costs, and enhance user experience.
What is caching
Caching is a technique used in computing to store frequently accessed data or computations in a faster, more easily accessible location. This allows for quicker retrieval of information, reducing the need to perform the same operations or fetch the same data repeatedly. In essence, caching acts as a short-term memory that helps improve system performance and efficiency.
“Storing frequently demanded things closer”
Benefits of caching
- Improved response time: Cached data can be retrieved much faster than recalculating or fetching from the original source especially in LLM systems.
- Reduced server load: By serving frequently requested data from cache, the main server experiences less strain.
- Bandwidth savings: Caching can significantly reduce the amount of data transferred over networks.
- Enhanced user experience: Faster response times lead to smoother interactions and increased user satisfaction.
- Cost-effectiveness: By reducing computational and network resources, caching can lead to lower operational costs.
LLM Cache
From an architectural perspective; caching in LLM systems shares similarities with traditional software caching:
— Both aim to improve performance by storing frequently accessed data.
— They use similar principles of temporal and spatial locality.
— Cache invalidation and updating strategies are crucial in both contexts.
However, LLM caching often deals with more complex, context-dependent data and may require more sophisticated caching strategies.
- Keyword Caching: This involves caching responses based on exact matches of input queries. It’s simpler but less flexible.
- Semantic Caching: This more advanced approach caches responses based on the meaning of queries, allowing for matches even when wording differs slightly.
Keyword caching
Consider the following queries:
- What is the capital of France?
- Tell me the capital of France!
To achieve keyword caching we will first tokenize both the queries:
- [“what”, “is”, “the”, “capital”, “of”, “france”] , and
2. [“tell”, “me”, “the”, “capital”, “of”, “france”]
Then normalize the tokens by removing stop words, stemming or lemmatization:
- [“capital”, “france”]
- [“capital”, “france”]
Now we can use the normalized words to generate a cache key.
Semantic caching
Use a technique like Sentence Embedding (e.g. S-BERT) to represent both queries as vectors.
Calculate the similarity between the vector representations.
If the similarity is above a threshold, consider the queries similar and use the same cache key.
Caching in AI Agents vs. RAG Architectures
- AI Agents: Caching for AI agents might focus more on storing intermediate reasoning steps or frequently used decision patterns. This can help agents make quicker decisions in similar scenarios.
- RAG (Retrieval-Augmented Generation) Architectures: Caching in RAG systems might prioritize storing frequently retrieved documents or snippets that are frequently relevant to queries, reducing the need for repeated retrievals from the knowledge base.
Now let’s look at the code for caching with LangChain library and caching examples with GPTCache package.
Cache with LangChain
Many popular frameworks like LangChain, llama_index and llama.cpp has some form of native caching support.
Langchian supports many popular integrations for caching including Redis, Elasticsearch, GPTCache and more. Check out the complete guide here.
In the following example we will use sqlite database to store cache keys, Milvus vector store to store embedding, our embedding model will be OpenAI embeddings API. We will use model from OpenAI via LangChain and the entire caching workflow will be managed by GPTCache.
First, import the required libraries:
from gptcache import cache
from gptcache.embedding import Onnx
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from gptcache.adapter.langchain_models import LangChainLLMs
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
import openaiStart the Milvus standalone server. Use docker compose instructions from the Milus page here.
Then, initialize the sqlite database and Milvus vector store client. You can also configure other vector storage, refer to VectorBase API.
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase(
'milvus',
host='192.168.1.6',
port='19530',
dimension=onnx.dimension,
collection_name='chatbot'
)
data_manager = get_data_manager(cache_base, vector_base)
cache.init(
pre_embedding_func=get_content_func,
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
openai.api_key="YOUR OPENAI KEY"
cache.set_openai_key()Then we will prepare the data using basic LangChain apis. Your workflow might call for more complex pre-processing.
loader = TextLoader('./f1-wikipedia.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()For this example we do similarity search over a vector database, but these documents could be fetched in any manner.
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={"host": "192.168.1.6", "port": "19530"},
)
query = "Who has the most championships?"
docs = vector_db.similarity_search(query)Invoke the run api.
llm = LangChainLLMs(llm=OpenAI(temperature=0))
chain = load_qa_chain(llm, chain_type="stuff")
query = "Who has the most championships?"
chain.run(input_documents=docs, question=query)You will see significant performance improvement when running same/similar query after the first run. In the first run, the system experiences a cache-miss and prepares the cache. In the subsequent runs, systems will experience cache-hit.
Cache with GPTCache
In the following examples, caching times will be more apparent.
First let’s initialize openai client and see the response time without any cache layer.
import time
import os
from openai import OpenAI
import openai
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI KEY"
client = OpenAI(
# Defaults to os.environ.get("OPENAI_API_KEY")
)
def response_text(openai_resp):
return openai_resp.choices[0].message.content
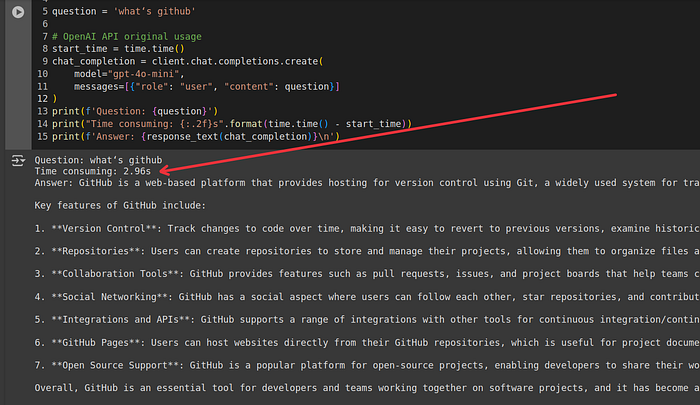
question = 'what‘s github'
# OpenAI API original usage
start_time = time.time()
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": question}]
)
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(chat_completion)}\n')For me, the average response time was around ~2.9 seconds with OpenAI’s GPT-4o-mini model.
Now we will use GPTCache and ask 4 similar questions on Github to see the response time after the first question.
Import the required functions:
import time
from gptcache import cache
from gptcache.adapter import openai
from gptcache.embedding import Onnx
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluationInitialize the cache layer. This time we will use sqlite database to store cache keys and FAISS in-memory vector storage. You can also configure other vector storage, refer to VectorBase API.
onnx = Onnx()
data_manager = get_data_manager(CacheBase("sqlite"), VectorBase("faiss", dimension=onnx.dimension))
cache.init(
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
openai.api_key="YOUR OPENAI KEY"
cache.set_openai_key()Call the ChatCompletion api on 4 similar questions:
def response_text(openai_resp):
return openai_resp['choices'][0]['message']['content']
questions = [
"what's github",
"can you explain what GitHub is",
"can you tell me more about GitHub",
"what is the purpose of GitHub"
]
for question in questions:
start_time = time.time()
response = openai.ChatCompletion.create(
model='gpt-4o-mini',
messages=[
{
'role': 'user',
'content': question
}
],
)
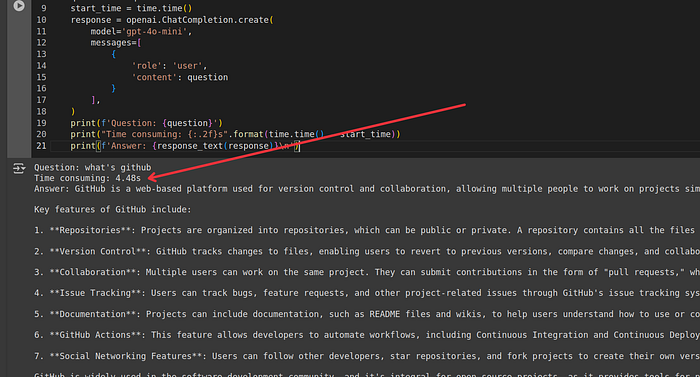
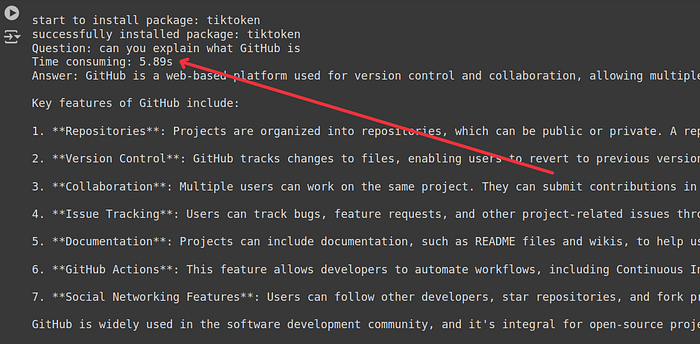
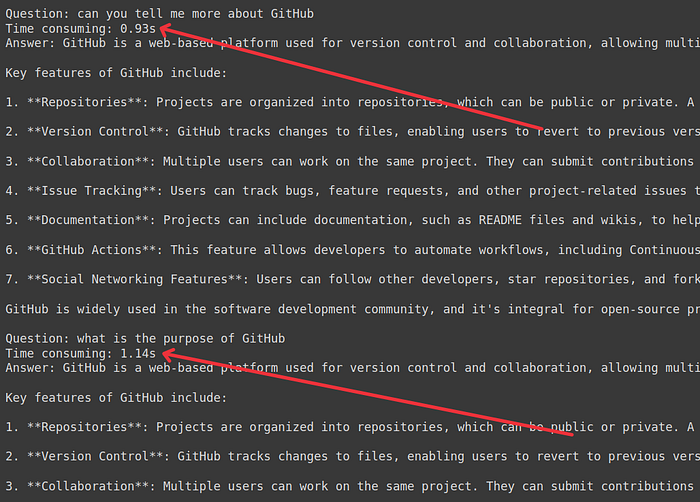
print(f'Question: {question}')
print("Time consuming: {:.2f}s".format(time.time() - start_time))
print(f'Answer: {response_text(response)}\n')Response time for the First query “what’s github” = 4.48s
Response time for the second query “can you explain what GitHub is” = 5.89s
And response time for the third and fourth queries “can you tell me more about GitHub”, “what is the purpose of GitHub” was 0.93s & 1.14s respectively.
You can also explore the sqlite database and see what information it is storing to manage the caching.
Challenges with LLM Caching
- Cache Coherence: Ensuring that cached data remains consistent with the underlying LLM as it gets updated.
- Context Sensitivity: LLM outputs can be highly dependent on context, making it challenging to determine when cached responses are applicable.
- Cache Size Management: Balancing between caching enough to be useful and not overwhelming system resources.
- Privacy Concerns: Ensuring that sensitive or personal information is not inadvertently stored in caches.
- Adaptive Caching: Developing strategies to dynamically adjust caching based on changing patterns of queries and responses.
Best Practices for Implementing LLM Caching
— Regular Cache Analysis: Continuously monitor and analyze cache performance to optimize strategies.
— Hybrid Approaches: Combine different caching techniques (e.g., keyword and semantic) for optimal results.
— Ethical Considerations: Implement caching with a focus on data privacy and ethical use of stored information.
You can connect with me on LinkedIn here: https://linkedin.com/in/maheshrajput
Happy learning 😃
