How to make a Recommender System Chatbot with LLMs
Make a session based apparel recommender system chatbot based on open source large language models or openai ChatGPT

In the rapidly evolving landscape of technology, chatbots have emerged as indispensable tools, catering to the escalating demand for seamless interactions for Question Answering, Action management, and much more.
Their utility can extend beyond mere conversational interfaces, finding profound application in recommendation systems.
Recommendation and search functionalities, intrinsic to enhancing user engagement, are closely interlinked — two facets of a dynamic coin.
This article unravels the intricacies of implementing and deploying a Recommender System chatbot, illuminating the convergence of chatbot capabilities with the sheer power of Large Language Models (LLMs) and machine learning powered recommendation system.
Project brief
We design and implement an apparel recommendation system that can
- Recommend apparels (non-personalized)
- Understand the occasion and recommend apparels for that occasion (example — what should I wear for my graduation ceremony?)
- Talk about the recommended items’ attributes, plus recommend similar items to the ones already recommended

Our overall system design (for development)

Tools employed:
- Jupyter notebook
- Sagemaker endpoint running Llama 2
- Aurora Postgres with pgvector extension
- Sentence Transformer
This is the system design of the deployment on AWS
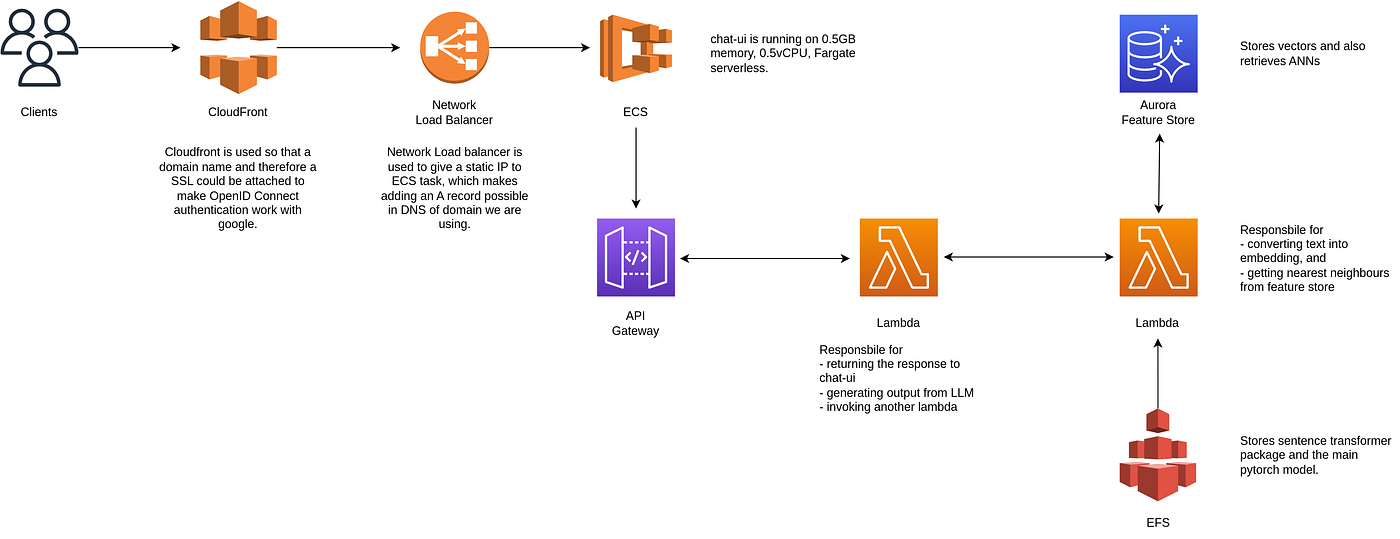
Services used:
- AWS CloudFront
- Network load balancer
- ECS Service
- API Gateway
- AWS Lambda functions
- Elastic File System
- Aurora Postgres Serverless with pgvector extension
Edit: 30th-Jan-2024
I have removed the demo app due to resource constrains. Please take a look at the demo video.
For a limited time, the following link hosts the chatbot end product of this project. Please note that one of the Lambdas takes 40 seconds to initialize due to Sentence Transformer, and the AWS API Endpoint has a timeout of 29seconds. If you encounter a network error on the first try, please retry after one minute to allow the Lambda to initialize:
Rate limits:
- Without login: 2 messages
- Messages per minute: 8
- Total traffic in one day: 1000 unique users
Which Recommendation engine to build?
From a business perspective, we usually employ a recommendation engine to help customers find the products relevant to their interests.
There are different ways to solve a recommendation problem:
- Simple rules, such as recommending popular apparels or items from popular brands
- Embedding-based models which rely on content-based or collaborative filtering
- Reformulating it into a ranking problem
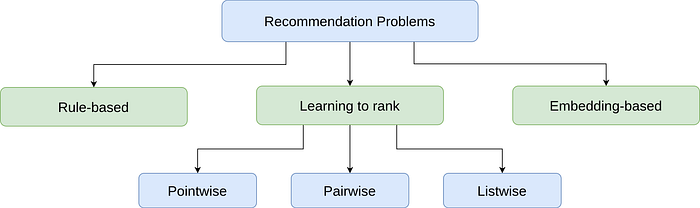
Rule-based methods are good starting points to form a baseline. However, ML-based approaches usually lead to better outcomes.
In this article, we frame the problem as similar item recommendation problem and use Embedding-based approach to capture the semantic meaning of user’s input.
Most recommendation systems rely on users’ historical interactions to understand their long-term interests. However, such recommendation systems may not be good at solving similar item problem. In our situation, recently viewed apparels are more informative than those viewed a long time ago.
Session-based recommendation systems
In this system, users’ interests are context-dependent and evolve fast. A good recommendation heavily depends on the user’s most recent interactions, not their generic interests.
Unlike a traditional recommendation system where users’ interests are context-independent and don’t change too frequently (like movie to watch, events to attend), in session-based recommendations, users’ interests are dynamic and evolve fast.
The goal of session-based recommendation system is to understand users’ short-term interests, based on their recent browsing history unlike a traditional recommendation system that aims to learn users’ generic interests.
How it can be done in our case
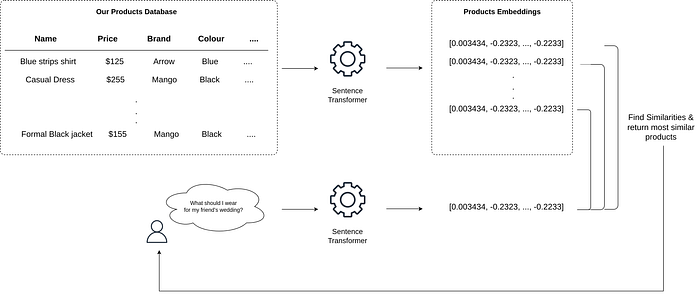
We will convert apparel features into embeddings using open source Sentence Transformer which converts sentences into dense embeddings using Siamese BERT-Networks.
Users’ messages to chatbot will be embedded using the same model that was used to transform products dataset, and using Approximate Nearest Neighbours approach we will retrieve the most similar products to the user’s query.
What does a chatbot need?
In the following article:
I talk about gathering data, preparing embeddings and building Approximate nearest neighbour models for chatbots.
Those function are same for any chatbot based on Retrieval-augmented generation (RAG).
In this article after building embeddings we will retrieve them using ANN based on user’s query and pass the product details of the nearest neighbours to the LLM as the context.
Combining recommendation engine and chatbot
This is tricky because for a chatbot to process all past interactions on each message for n no. of users is a fast-track road to bankruptcy owing to stratospheric levels of cloud bills.
So we will pass only a subset of users’ previous interactions to the chatbot and hope that LLM can understand the interests from the limited information.
Our flow will be like this:
- User asks for an apparel
- First LLM will only provide apparel suggestions and nothing else
- We combine user’s original text with first LLM’s output and convert that into dense embedding
- We find the similar products from vector storage to the embedding generated in previous step
- We pass the list of retrieved apparels with the user’s chat history to another LLM and ask it to act as a recommendation engine chatbot
We will be using 2 LLMs,
- One to understand the user’s query — for example if user asks for some suggestion based on a particular occasion like party, wedding, funeral etc then this LLM will output various apparel choices like dress, suit, t-shirts etc based on the occasion. On the other hand if user asks for a sunflower dress LLM can just output ‘sunflower dress’ as it is.
- Second LLM acts as the main recommender system. It will understand user’s whole chat input plus the recommended items, to kind of work as a filtering service too.
For both the LLMs you can use either ChatGPT or LLAMA2 hosted on Sagemaker.
And for chat interface I used HuggingFace chat-ui code base.
I have presented 4 different ways to deploy a LLM based chatbot in the following article:
Allright, now let’s see some code 😎
Dataset
I had this Amazon fashion products dataset which contained 183,138 products crawled from amazon.com.

This dataset was perfect, it had product names, prices, brands, descriptions and most importantly images 😍

So I decided to convert product_type_name + few other related features to embeddings using Sentence Transformer.
But when I searched for simple keywords like “blue shirts”, it would give me products that has “blue shirt” keyword in their features BUT the apparels in the images had different colour (yellow, black etc).
So instead of converting textual data into embeddings, I decided to convert the product images to first text and then convert that text into embeddings. This should in theory give much better description about the product in the image, or I though so.
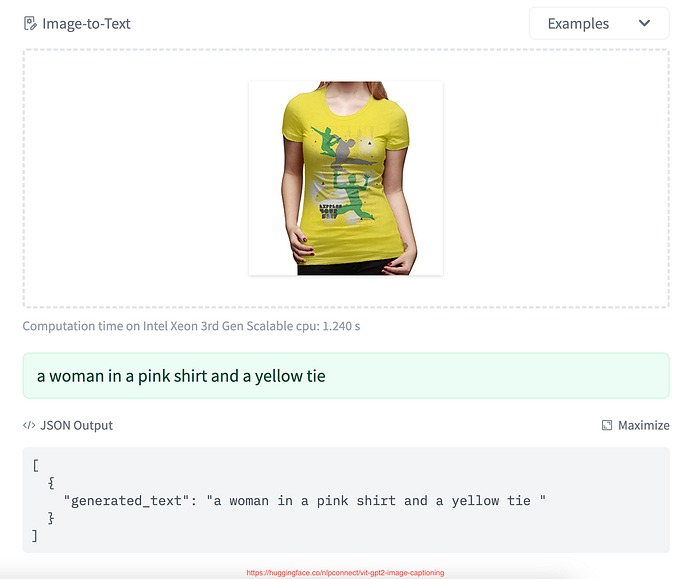
It turns out that none of the open source light weight models are good for describing the apparel correctly in the image.
Take a look at the following image, most models can accurately describe it as — “Black full sleeves shirt with collar”

But following are few samples from lots of failed descriptions:

Model prediction: “a close up of a woman wearing a camouflage shirt”

Model prediction: “a close up of a woman in a white shirt and brown pants”
Descriptions like this will damage the recommendation system because we are not selling brown pants in this product.

Model prediction: “a woman wearing a blue top with white jeans and white shoes”

Model prediction — “a pink tank top with a white logo on the front”

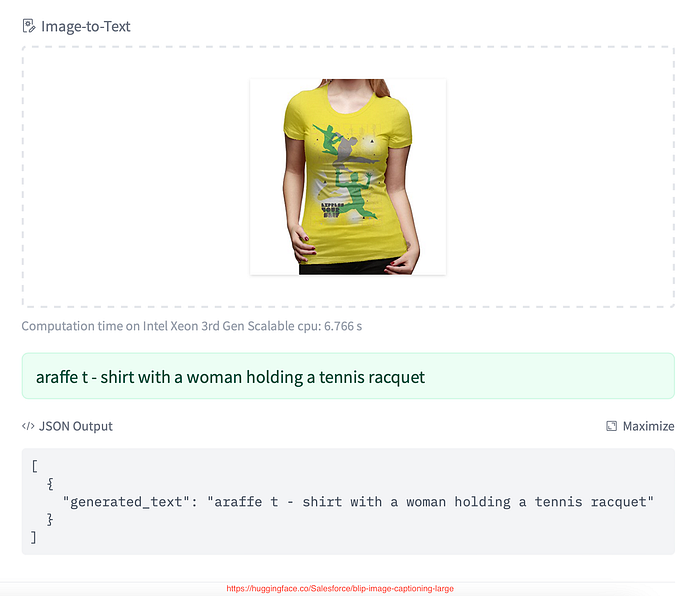
Model predictions — “araffe t — shirt with a woman holding a tennis racquet”
Different models’ predictions on same image:
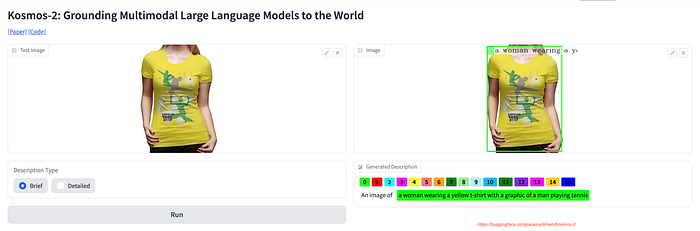
There are few image to text models that are able to provide accurate description, but those models are GPU intensive and I didn’t had the zeal to invest in them.
Final Dataset Selection
A quick Kaggle search and I landed on the Myntra’s fashion clothing products dataset. Source.
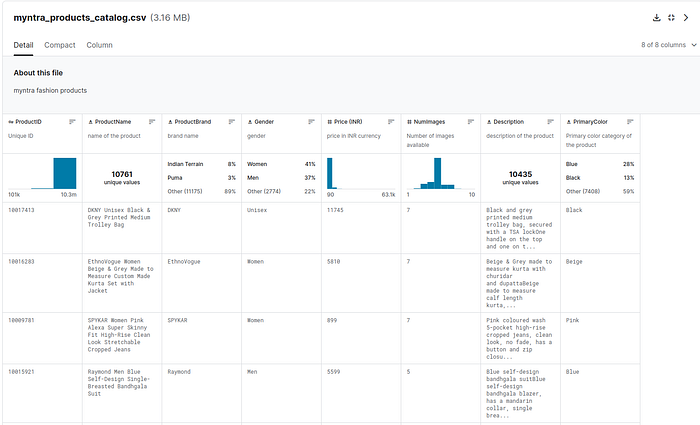
Myntra is a major Indian fashion e-commerce company in India.
This dataset has 12,491 items and the product descriptions are more cleaner than what Amazon Fashion dataset has, but with the drawback is not having product images.
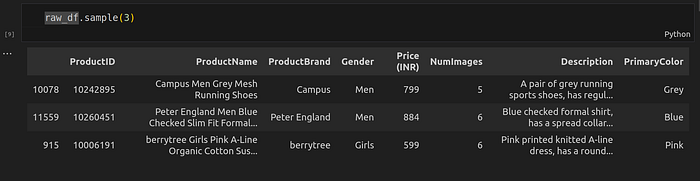
Embeddings
I chose to convert only the ProductName feature into embeddings because it described the item well enough.

I used all-mpnet-base-v2 model of Sentence Transformer package which is their highest performing model, but slower than everyone’s favourite all-MiniLM-L12-v2.
Where to Store embeddings and how to query ANN
You can go with qdrant , chroma or any other dedicated vector databases and face no problem in the implementation.
I used pgvector extension of postgres because I wanted to deploy it on AWS and pgvector is supported by Aurora Serverless. Plus this helped in managing 1 less server.
For ANN, pgvector supports creating IVFFlat or HNSW (not for SQLAlchemy) index on the embeddings column, which can be queried using l2, cosine or dot product.
Once we had the embeddings ready, we just pushed the products data + their embeddings to the feature store.
The notebook containing data preparation code can be retrieved from the following repository:
Functions for querying recommendations
Before we do that, let’s first deploy Llama 2 model on sagemaker endpoint.
Use the “Deploy LLM to a Sagemaker endpoint” section from the article:
Or if you want to use OpenAI ChatGPT model, you can use following function:
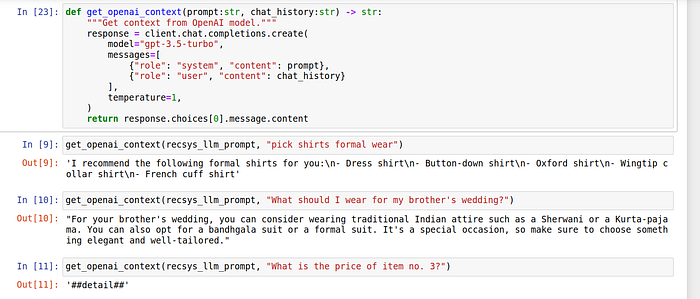
def get_openai_context(prompt:str, chat_history:str) -> str:
"""Get context from OpenAI model."""
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": chat_history}
],
temperature=1,
)
return response.choices[0].message.contentResult of some basic queries:
This is the prompt given to LLM:
You are a apparel recommender agent for an Indian apparel company. Your job is to suggest different types of apparel one can wear based on the user's query. You can understand the occasion and recommend the correct apparel items for the occasion if applicable, or just output that specific apparels if user is already very specific. Below are few examples with reasons as to why the particular item is recommended:
```
User question - show me blue shirts
Your response - blue shirts
Reason for recommendation - user is already specifc in their query, nothing to recommend
User question - What can I wear for office party?
Your response - semi formal dress, suit, office party, dress
Reason for recommendation - recommend apparel choices based on occassion
User question - I am doing shopping for trekking in mountains what do you suggest
Your response - heavy jacket, jeans, boots, winsheild, seweater.
Reason for recommendation - recommend apparel choices based on occassion
User question - What should one person wear for their child's graduation ceremony?
Your response - Dress or pantsuit, Dress shirt, heels or dress shoes, suit, tie
Reason for recommendation - recommend apparel choices based on occassion
User question - sunflower dress
Your response - sunflower dress
Reason for recommendation - user is specific about their query, nothing to recommend
User question - What's is the price of 2nd item
Your response - '##detail##'
Reason for recommendation - User is asking for information related to product already recommender, in that case you should only return '##detail##'
User question - what is the price of 4th item in the list
Your response - '##detail##'
Reason for recommendation - User is asking for information related to product already recommender, in that case you should only return '##detail##'
User question - What's are their brand names?
Your response - '##detail##'
Reason for recommendation - User is asking for information related to product already recommender, in that case you should only return '##detail##'
User question - show me more products with similar brand to this item
Your response - your respone must be the brand name of the item
Reason for recommendation - User is asking for similar products, return the original product
User question - do you have more red dresses in similar patters
Your response - your response must be the name of that red dress only
Reason for recommendation - User is asking for similar products, return the original product
```
Only suggest the apparels or only relevant information, do not return anything else.For final recommendations:
- We will convert user’s text into embeddings and add first LLM’s context:
def generate_query_embeddings(user_message:str, embedding_model):
"""Generate user message embeddings."""
openai_context = get_openai_context(recsys_llm_prompt, user_message)
query_emb = embedding_model.encode(user_message + " " + openai_context)
return query_emb2. Then we will search ANN from our feature store:
def query_product_names_from_embeddings(query_emb, engine, Table, top_k):
"""Search ANN products using embeddings."""
with Session(engine) as session:
stmt = sqlalchemy.select(
Table.pid, Table.pname, Table.brand, Table.gender, Table.gender, Table.price, Table.description, Table.color
).order_by(Table.embeddings.l2_distance(query_emb)).limit(top_k)
stmt_response = session.execute(stmt).mappings().all()
return stmt_responseTying together above functions:
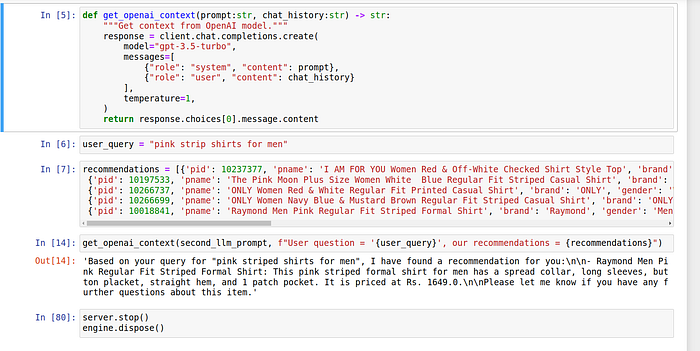
def get_recommendations(user_message:str, embedding_model, engine, Table, top_k=5):
"""Get recommendations."""
embeddings = generate_query_embeddings(user_message, embedding_model)
p_names = query_product_names_from_embeddings(embeddings, engine, Table, top_k)
return p_namesSample query:
response = get_recommendations("pink strip shirts for men", model, engine, Products)Response:

Passing recommendations + user’s message to second LLM
Now we can use the same get_openai_context function or sagemaker endpoint, and pass second LLM’s prompt + user’s chat history that has user’s message and our recommendations:
Our second LLM prompt:
You can recommendation engine chatbot agent for an Indian apparel brand.
You are provided with users questions and some apparel recommendations from the brand's database.
Your job is to present the most relevant items from the data give to you.
If user is asking a clarifying question about one of the recommended item, like what is it's price or brand, then answer that question from its description.
Do not answer anything else apart from apparel recommendation from the company's database.Sample response from second LLM:
Above code is available in the recommender-with-both-llms.ipynb jupyter notebook in this repository:
Deployment 🫣
One word sums up the deployment for this project:
Complicated
Because I was using HuggingFace chat-ui for chat interface, I decided to deploy that app on ECS.
For the whole back-end system, I utilized two lambdas:
- First lambda is responsible for returning the final output to the chat-ui app, but it does not do the whole work. It takes user’s message and asks the first LLM to retrive the context for this text. It then passes user’s message plus LLM’s context to another lambda.
- Second lambda has Sentence Transformer model packaged in EFS. You can also use dedicated endpoint for this, but I decided to subsidise on billing. So this lambda converts the payload received from first lambda into dense embeddings using Sentence Transformer (by the way, I also store the pytorch model in EFS) and lambda also queries nearest neighbours from database.
- First lambda upon receiving nearest neighbours (or recommendations), appends them to user’s chat history (which also has the user question) to send to second LLM for final output, which is then return to the API endpoint.
The main bottleneck is the second lambda’s Sentence Transformer package. Cold start initialisation takes around 50 seconds. We can use some alternatives to shorten the overall response time.
One drawback of using python runtime lambda with AWS API Gateway is that it doesn’t support streaming output. So we loose words appearing like a typewriter. We can use nodejs runtime to yield a streaming response or use FastAPI streaming output function on a self hosted solution.
Demo 😍
Edit: 30th-Jan-2024
I have removed the demo app due to resource constrains. Please take a look at the demo video.
For a limited time, because running two sagemaker endpoints with GPU are very very expensive, you can play with the chatbot at this link:
Rate limits:
- Without login: 2 messages per user
- Messages per minute: 8 per user
- Total traffic in one day: 1000 users
Code for development phase is available in this repository:
You can connect we me on linkedin:
