Build a Customer Support Assistant with Llama3.1
Use LLM Agents and Amazon Bedrock to Solve Customer Queries with AI: A Guide to Building and Deploying a Support Assistant with Llama3.1

Introduction
Problem
Businesses often face the challenge of handling a large volume of customer inquiries. These queries can range from mundane questions like “What is the status of my order?” to more complex issues requiring human intervention. The sheer volume of repetitive queries can overwhelm customer support teams, leading to longer response times and reduced customer satisfaction. Additionally, utilizing human resources for simple, routine queries is inefficient and costly. There’s a growing need for automated solutions that can handle routine queries effectively, allowing human agents to focus on escalated cases that require nuanced problem-solving.
Solution
The introduction of Large Language Model (LLM) agents offers a promising solution to this problem. An LLM agent can respond to user queries by accessing and interpreting data from a company’s database, handling simple operations such as checking order status, retrieving account information, and answering FAQs. By automating these routine tasks, an LLM agent ensures faster resolution times and frees up human resources for more complex customer support scenarios. In this guide, we’ll explore how to build a customer support assistant using the Llama3.1 model from Amazon Bedrock Tools api.
At the end, we will have the assistant running locally in our machine and making calls to a fake database:

LLM Agents
What are LLM agents
LLM agents are specialized applications built on large language models like Llama3.1, designed to perform specific tasks or functions. Unlike general LLMs, which generate human-like text based on a given prompt, LLM agents are equipped with additional capabilities such as accessing external databases, performing operations, and making decisions based on predefined rules. They are tailored to handle specific use cases, such as customer support, where they can interact with users, retrieve information, and execute commands based on the context of the conversation.
While general LLMs are powerful in generating coherent text and understanding language, LLM agents take this a step further by integrating with external systems, allowing them to perform real-world tasks beyond just text generation.
Agent have set of instructions, a foundation model, a set of available actions and knowledge bases, which enables then to execute complex tasks.
A generative model can answer a general question, or a question related to your documentation, like “I can’t see my meetings?, How do I book a meeting?”. An agent, using a foundational model as their reasoning logic and external data sources like your APIs, can return the user their no. of booked meetings, or directly schedule a meeting from the interaction screen.
There are many agents in the “general purpose” category, and also specialized agents for task specific purpose like code assistant (Amazon CodeWhisperer, Copilot), writing assistant, system design (Amazon Q) , wikipedia summary, etc.
AI agents landscape:

Creating a Basic Agent from Scratch Using Python
Let’s create a simple LLM agent from scratch using Python. This amazing medium article demonstrates how to build an agent without relying on any libraries or frameworks.
Custom Support Assistant
Now, let’s create a more sophisticated customer support assistant using the Llama3.1 model from Bedrock Tools. This agent will be able to perform more complex tasks, such as looking up user data from a database and executing simple operations like viewing shipping status of an order.
Defining Capabilities and boundaries
Before building our assistant, it’s essential to define what actions the agent can perform and establish clear boundaries for its operation. In a production environment, these capabilities and boundaries are crucial to ensure the agent operates effectively and securely.
Capabilities:
- Respond to common customer queries (e.g., order status, return policy).
- Access and retrieve user data from a database.
- Perform simple operations like viewing order status, updating customer information, etc.
Boundaries:
- The agent should not execute actions that require human judgment, such as processing refunds or handling escalations.
- It should operate within the defined scope and not access sensitive data unless explicitly permitted.
- Error handling and fallback mechanisms should be in place for unsupported queries.
Architecture
The system architecture for our solution involves several components working together:
- LLM Agent: The core of the system, built using the Llama3.1 or Claude 3.5 Sonnet model, which handles natural language processing and decision-making.
- Database: Stores customer data and other relevant information that the agent can query.
- API Layer: Facilitates communication between the LLM agent and the database, allowing the agent to retrieve and manipulate data.
- User Interface: A frontend interface (e.g., a chatbot interface) where customers interact with the support assistant.
Code
Before we examine the code, please ensure you have the following:
- Knowledge of Python and the boto3 library.
- A working AWS account with model access enabled in Bedrock.
- A virtual environment with Python and boto3 installed.
Code Walkthrough
from datetime import datetime
import json
from typing import Any, Dict, List
import boto3
from botocore.exceptions import ClientError
# Initialize a Boto3 session and create a Bedrock runtime client
session = boto3.Session()
region = "us-east-1" # us-west-2 has better runtime quota
bedrock_client = session.client(service_name = 'bedrock-runtime', region_name = region)First, we import the necessary packages and create an instance of the boto3 Bedrock runtime client, called bedrock_client, for the us-east-1 region. If your AWS account has the us-west-2 availability zone (AZ) enabled, use that instead. At the time of writing, Llama3.1 models are only available in the us-west-2 AZ and it also has a larger runtime quota for the claude-3.5-sonnet model (250 requests per minute) compared to the us-east-1 AZ, which supports only 50 requests per minute.
# Define available models with their respective request limits
available_models = {
"sonnet3-5": "anthropic.claude-3-5-sonnet-20240620-v1:0", # 50 requests per min
"sonnet": "anthropic.claude-3-sonnet-20240229-v1:0", # 500 requests per min
"llama31-70b": "meta.llama3-1-70b-instruct-v1:0", # 400 requests per min
"llama31-405b": "meta.llama3-1-405b-instruct-v1:0", # 50 requests per min
}
modelId = available_models["sonnet3-5"] # Select model for conversationNext, we create a mapping of model IDs in Bedrock. Currently not all the models available in Amazon Bedrock support tool use. Please check the list of supported models from Amazon Bedrock user guide here.
class FakeDatabase:
"""Sample fake database implementation."""
def __init__(self):
self.customers = [
{"id": "1213210", "name": "John Doe", "email": "john@gmail.com", "phone": "123-456-7890", "username": "johndoe"},
{"id": "2837622", "name": "Priya Patel", "email": "priya@candy.com", "phone": "987-654-3210", "username": "priya123"},
{"id": "3924156", "name": "Liam Nguyen", "email": "lnguyen@yahoo.com", "phone": "555-123-4567", "username": "liamn"},
{"id": "4782901", "name": "Aaliyah Davis", "email": "aaliyahd@hotmail.com", "phone": "111-222-3333", "username": "adavis"},
{"id": "5190753", "name": "Hiroshi Nakamura", "email": "hiroshi@gmail.com", "phone": "444-555-6666", "username": "hiroshin"},
{"id": "6824095", "name": "Fatima Ahmed", "email": "fatimaa@outlook.com", "phone": "777-888-9999", "username": "fatimaahmed"},
{"id": "7135680", "name": "Alejandro Rodriguez", "email": "arodriguez@protonmail.com", "phone": "222-333-4444", "username": "alexr"},
{"id": "8259147", "name": "Megan Anderson", "email": "megana@gmail.com", "phone": "666-777-8888", "username": "manderson"},
{"id": "9603481", "name": "Kwame Osei", "email": "kwameo@yahoo.com", "phone": "999-000-1111", "username": "kwameo"},
{"id": "1057426", "name": "Mei Lin", "email": "meilin@gmail.com", "phone": "333-444-5555", "username": "mlin"}
]
self.orders = [
{"id": "24601", "customer_id": "1213210", "product": "Wireless Headphones", "quantity": 1, "price": 79.99, "status": "Shipped"},
{"id": "13579", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 2, "price": 19.99, "status": "Processing"},
{"id": "97531", "customer_id": "2837622", "product": "Bluetooth Speaker", "quantity": 1, "price": "49.99", "status": "Shipped"},
{"id": "86420", "customer_id": "3924156", "product": "Fitness Tracker", "quantity": 1, "price": 129.99, "status": "Delivered"},
{"id": "54321", "customer_id": "4782901", "product": "Laptop Sleeve", "quantity": 3, "price": 24.99, "status": "Shipped"},
{"id": "19283", "customer_id": "5190753", "product": "Wireless Mouse", "quantity": 1, "price": 34.99, "status": "Processing"},
{"id": "74651", "customer_id": "6824095", "product": "Gaming Keyboard", "quantity": 1, "price": 89.99, "status": "Delivered"},
{"id": "30298", "customer_id": "7135680", "product": "Portable Charger", "quantity": 2, "price": 29.99, "status": "Shipped"},
{"id": "47652", "customer_id": "8259147", "product": "Smartwatch", "quantity": 1, "price": 199.99, "status": "Processing"},
{"id": "61984", "customer_id": "9603481", "product": "Noise-Cancelling Headphones", "quantity": 1, "price": 149.99, "status": "Shipped"},
{"id": "58243", "customer_id": "1057426", "product": "Wireless Earbuds", "quantity": 2, "price": 99.99, "status": "Delivered"},
{"id": "90357", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 1, "price": 19.99, "status": "Shipped"},
{"id": "28164", "customer_id": "2837622", "product": "Wireless Headphones", "quantity": 2, "price": 79.99, "status": "Processing"}
]
def get_user(self, key:str, value:str) -> Dict[str, str]:
"""Return metadata of user."""
if key in {"email", "phone", "username"}:
for customer in self.customers:
if customer[key] == value:
return customer
return f"Couldn't find a user with {key} of {value}"
else:
raise ValueError(f"Invalid key: {key}")
return None
def get_order_by_id(self, order_id: str) -> Dict[str, str]:
"""Return metadata of the order using order id."""
for order in self.orders:
if order["id"] == order_id:
return order
return None
def get_customer_orders(self, customer_id: str) -> List[Dict[str, str]]:
"""Return a list of orders for a specific customer."""
return [order for order in self.orders if order["customer_id"] == customer_id]
def cancel_order(self, order_id: str) -> str:
"""Cancel an order if it's in 'Processing' status."""
order = self.get_order_by_id(order_id)
if order:
if order["status"] == "Processing":
order["status"] = "Cancelled"
return "Cancelled the order"
else:
return "Order has already shipped. Can't cancel it."
return "Can't find that order!"For this demo, we implement a mock database class with a predefined list of customers and their orders. This mock database class also includes methods to retrieve data from the database.
get_user: Returns the userget_order_by_id: Returns the order using order idget_customer_orders: Returns all the orders of a particular customercancel_order: Cancel an order if it’s in ‘Processing’ status.
# Define all the tools avilable to the model
tool_config = {
"tools": [
{
"toolSpec": {
"name": "get_user",
"description": "Looks up a user by email, phone, or username.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"key": {
"type": "string",
"enum": ["email", "phone", "username"],
"description": "The attribute to search for a user by (email, phone, or username).",
},
"value": {
"type": "string",
"description": "The value to match for the specified attribute.",
},
},
"required": ["key", "value"],
}
},
}
},
{
"toolSpec": {
"name": "get_order_by_id",
"description": "Retrieves the details of a specific order based on the order ID. Returns the order ID, product name, quantity, price, and order status.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier for the order.",
}
},
"required": ["order_id"],
}
},
}
},
{
"toolSpec": {
"name": "get_customer_orders",
"description": "Retrieves the list of orders belonging to a user based on a user's customer id.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "The customer_id belonging to the user",
}
},
"required": ["customer_id"],
}
},
}
},
{
"toolSpec": {
"name": "cancel_order",
"description": "Cancels an order based on a provided order_id. Only orders that are 'processing' can be cancelled",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The order_id pertaining to a particular order",
}
},
"required": ["order_id"],
}
},
}
},
],
"toolChoice": {"auto": {}},
}Next we define a tool_config .
You can use the Amazon Bedrock API to give a model access to tools that can help it generate responses for messages that you send to the model. For example, you might have a chat application that lets users find out out the most popular song played on a radio station. To answer a request for the most popular song, a model needs a tool that can query and return the song information.
Tool use with models is also known as Function calling.
In Amazon Bedrock, the model doesn’t directly call the tool. Rather, when you send a message to a model, you also supply a definition for one or more tools that could potentially help the model generate a response. In this example, you would supply a definition for tools that returns the customer details, order details or cancel an order. If the model determines that it needs the tool to generate a response for the message, the model responds with a request for you to call the tool. It also includes the input parameters (the required customer id or order id) to pass to the tool.
In your code, you call the tool on the model’s behalf. In this scenario, assume the tool implementation is an API. The tool could just as easily be a database, Lambda function, or some other software. You decide how you want to implement the tool. You then continue the conversation with the model by supplying a message with the result from the tool. Finally the model generates a response for the original message that includes the tool results that you sent to the model.
In our example, we define all the functions we want the chatbot to execute in the tool_config . Refer to the Amazon Bedrock documentation for more information on the ToolConfiguration API.
def process_tool_call(tool_name: str, tool_input: Any) -> Any:
"""Process the tool call based on the tool name and input."""
if tool_name == "get_user":
return db.get_user(tool_input["key"], tool_input["value"])
elif tool_name == "get_order_by_id":
return db.get_order_by_id(tool_input["order_id"])
elif tool_name == "get_customer_orders":
return db.get_customer_orders(tool_input["customer_id"])
elif tool_name == "cancel_order":
return db.cancel_order(tool_input["order_id"])Since our application code will call the required tools on behalf of the LLM, we package all the tools into a single function. The process_tool_call function executes the appropriate functions based on the tool_name and tool_input provided by the LLM.
def simple_chat():
"""Main chat function that interacts with the user and the LLM."""
system_prompt = """
You are a customer support chat bot for an online retailer called TechNova.
Your job is to help users look up their account, orders, and cancel orders.
Be helpful and brief in your responses.
You have access to a set of tools, but only use them when needed.
If you do not have enough information to use a tool correctly, ask a user follow up questions to get the required inputs.
Do not call any of the tools unless you have the required data from a user.
"""
# Initial user message
user_message = input("\nUser: ")
messages = [{"role": "user", "content": [{"text": user_message}]}]
while True:
# If the last message is from the assistant, get another input from the user
if messages[-1].get("role") == "assistant":
user_message = input("\nUser: ")
messages.append({"role": "user", "content": [{"text": user_message}]})
# Parameters for API request to the Bedrock model
converse_api_params = {
"modelId": modelId,
"system": [{"text": system_prompt}],
"messages": messages,
"inferenceConfig": {"maxTokens": 4096},
"toolConfig": tool_config, # Pass the tool config
}
# Get response from Bedrock model
response = bedrock_client.converse(**converse_api_params)
# Append assistant's message to the conversation
messages.append(
{"role": "assistant", "content": response["output"]["message"]["content"]}
)
# If the model wants to use a tool, process the tool call
if response["stopReason"] == "tool_use":
tool_use = response["output"]["message"]["content"][
-1
] # Naive approach assumes only 1 tool is called at a time
tool_id = tool_use["toolUse"]["toolUseId"]
tool_name = tool_use["toolUse"]["name"]
tool_input = tool_use["toolUse"]["input"]
print(f"Claude wants to use the {tool_name} tool")
print(f"Tool Input:")
print(json.dumps(tool_input, indent=2))
# Run the underlying tool functionality on the fake database
tool_result = process_tool_call(tool_name, tool_input)
print(f"\nTool Result:")
print(json.dumps(tool_result, indent=2))
# Append tool result message
messages.append(
{
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_id,
"content": [{"text": str(tool_result)}],
}
}
],
}
)
else:
# If the model does not want to use a tool, just print the text response
print(
"\nTechNova Support:"
+ f"{response['output']['message']['content'][0]['text']}"
)The simple_chat function handles user interaction, invokes the LLM, and passes the tool response back to the LLM.
An important line in this function is response["stopReason"] == "tool_use". This determines if the LLM wants to use a tool and, when parsed further, indicates which tool the LLM intends to invoke.
An example of response object of bedrock-runtime converse api:
{
'ResponseMetadata': {
'RequestId': '07f323a7-cc52-4813-9d1b-83e5c3ae932a',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'date': 'Thu, 08 Aug 2024 10:52:59 GMT',
'content-type': 'application/json',
'content-length': '519',
'connection': 'keep-alive',
'x-amzn-requestid': '07f323a7-cc52-4813-9d1b-83e5c3ae932a'
},
'RetryAttempts': 0
},
'output': {
'message': {
'role': 'assistant', 'content': [
{
'text': "Certainly! I'll search for search for your orders. Let me use our search tool to find that information for you."
}, {
'toolUse': {
'toolUseId': 'tooluse_8C_XIwrAROC3t3eEu5FCVw',
'name': 'get_customer_orders',
'input': {'customer_id': '1213210'}
}
}
]
}
},
'stopReason': 'tool_use',
'usage': {'inputTokens': 672, 'outputTokens': 103, 'totalTokens': 775},
'metrics': {'latencyMs': 2431}
}Refer to the Amazon Bedrock API Reference for more details about the Converse API.
Once we invoke the required tool or function using our process_tool_call function, we pass the function's response back to the LLM to generate a response for the end user.
Please note that we are using the Converse API of the
boto3Bedrock runtime client. You can also use the Converse Stream API to generate a streaming response. For more details, refer to the Amazon Bedrock API Reference for the Converse Stream API and the Boto3 documentation on the Converse Stream API.
Running in local terminal
Once you have everything set up correctly, run the Python file from inside your virtual environment using:
# From inside the virtual environment
python main.pyDeploy on EC2
You can deploy the chatbot on an EC2 instance for demonstration purposes using a Gradio app, which provides a chatbot-like interface with just a few lines of code and integrates seamlessly with our main function.
Gradio
Gradio is an open-source Python library that simplifies the process of building and deploying web-based machine learning demos. It allows developers to create intuitive web interfaces for their models with minimal coding, making it easier to deploy and share models with others.
Let’s write a chat function that responds Yes or No randomly using gradio.
Here’s our chat function (please execute pip install gradio in your virtual environment if you don’t have it already installed):
import random
import gradio as gr
def random_response(message, history):
return random.choice(["Yes", "No"])
gr.ChatInterface(random_response).launch()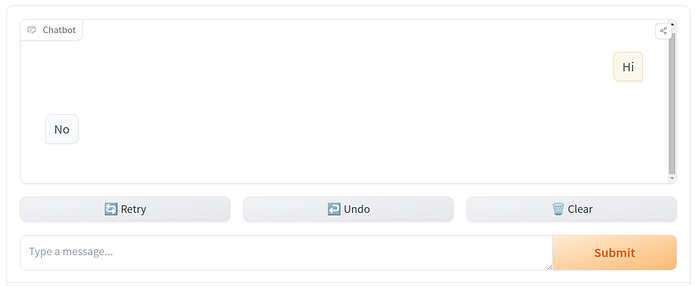
Read more about the gradio chatbot documentation here.
Running a Gradio App on your Web Server with Nginx
Let’s deploy our chatbot agent on EC2 with Nginx.
Install Nginx and create new conda env
- Create an EC2 instance with at least 2–3 GB of memory. You can also deploy it on your Kubernetes or ECS cluster. Make sure to modify the Nginx configuration file to match your setup.
2. SSH into your EC2 instance and install Nginx:
sudo yum update -y
sudo amazon-linux-extras install nginx1.12
sudo systemctl start nginx
sudo systemctl enable nginx
sudo systemctl status nginx3. Install Miniconda to manage Python packages:
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh4. Create a new Conda environment with Python 3, and install boto3 and gradio:
conda create --name gradio-demo python=3.12 pip -y
conda activate gradio-demo
pip install --no-cache-dir gradio boto35. Create a new Python file for your chatbot and Gradio code. Copy all your code into this file:
vim gradio_demo.pyAlternatively, you can use scp to copy the file directly from your local machine to the remote instance.
Setup Nginx
Now we will set up Nginx to redirect all traffic from the /gradio-demo path to the local server started by the gradio_demo.py file. Refer to the official documentation for running Gradio with Nginx here.
- Edit the Nginx configuration file located at
/etc/nginx/nginx.conf:
vim /etc/nginx/nginx.conf2. In the http block, add the following lines to include server block configurations from a separate file:
server_names_hash_bucket_size 128;
include /etc/nginx/sites-enabled/*;3. Create a new file in the /etc/nginx/sites-available directory (create the directory if it does not already exist), using a filename that represents your app, for example: sudo vim /etc/nginx/sites-available/my_gradio_app :
sudo mkdir -p /etc/nginx/sites-enabled
sudo vim /etc/nginx/sites-available/my_gradio_appPaste the following contents in the my_gradio_app file:
server {
listen 80;
server_name www.ec2-12-34-56-78.us-west-2.compute.amazonaws.com; # Change this to your domain name
location /gradio-demo/ { # Change this if you'd like to server your Gradio app on a different path
proxy_pass http://127.0.0.1:7860/; # Change this if your Gradio app will be running on a different port
proxy_buffering off;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}4. Create a symbolic link to this file in the /etc/nginx/sites-enabled directory:
sudo ln -s /etc/nginx/sites-available/my_gradio_app /etc/nginx/sites-enabled/5. Update the gradio_demo.py file to set the root path in the Gradio launch API:
.launch(root_path="/gradio-demo")6. Check the Nginx configuration and restart Nginx:
sudo nginx -t
sudo systemctl restart nginxIf you encounter errors with the nginx -t command, resolve those errors before proceeding.
Run the gradio_demo.py file in the background. You can use either nohup or tmux:
# From inside the Conda environment
nohup python gradio_demo.py &Access the EC2 DNS URL and append /gradio-demo/ to see your chatbot agent on the Gradio interface.
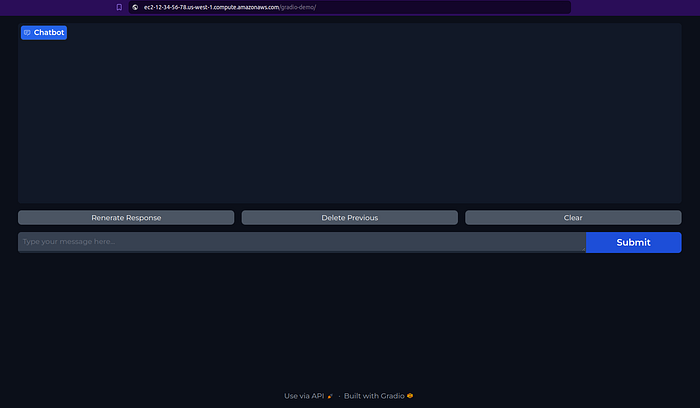
Summary
In this article, we explored how to build a customer support assistant using the Llama3.1 or Claude 3.5 Sonnet model from Bedrock Tools. We began by defining the problem of handling repetitive customer queries and how LLM agents offer a solution. We then discussed the concept of LLM agents and how they differ from general LLMs. After that, we walked through creating a basic agent in Python and then developed a more complex customer support assistant using the models in Amazon Bedrock. We also covered deploying the assistant on EC2, including an example of using Gradio to create a web interface. By automating routine customer support tasks, businesses can enhance efficiency, reduce costs, and improve customer satisfaction.
In a production setting, you can pass the logged-in user’s name and ID to the system prompt so that the LLM does not have to ask for basic details from a logged-in user. Some actions, such as canceling an order, may require additional gatekeeping. Additionally, if a customer is upset or becomes aggressive, the LLM should be instructed to escalate the case to a human assistant.
You can connect with me on LinkedIn: https://linkedin.com/in/maheshrajput
Thank you for reading 😊
